Sunday, November 15, 2020
Wednesday, October 7, 2020

Sunday, August 30, 2020
Iterable and Iterator in Python using Aladdin story.
Generally we use for-loops to iterate or traverse across the elements within a List or Tuples.

In the for-loop after processing the first element in the list control moves to the next element , this process of traveling from one element to other is called Iteration. For loop works in the same way for Tuples, Dictionaries, Strings and Sets.

There are two ways to do the same iteration process without using For-Loop. The first method is Indexing

But this indexing method can be used only for List,Tuples and strings.They cannot be used for Sets and Dictionaries because they are unordered.

Iterator Protocol:
The second method we can use is Iterator protocol. Iterator protocol is nothing but working with Iterator and Iterable. Most of us are confused with these two terms Iterable and Iterator.
Let’s have a close look at them now.

Everything that we can loop over is called a Iterable. In the above fig of for Loop list is an iterable.
Now these Iterables do give us the Iterators. They do give these iterators using a function Iter().Iterable usually call this Inbuilt function iter() and generate the Iterator. Using this Iterator we can traverse across the individual elements in the Iterable.
Let’s use our friend Aladdin to explain this Iterable concept.
Consider Aladdin as the Literable and the Genie as the iterator which does things for Aladin.Aladdin brings the Genie out using the Magic lamp, so now the magic lamp is our ITER() object.
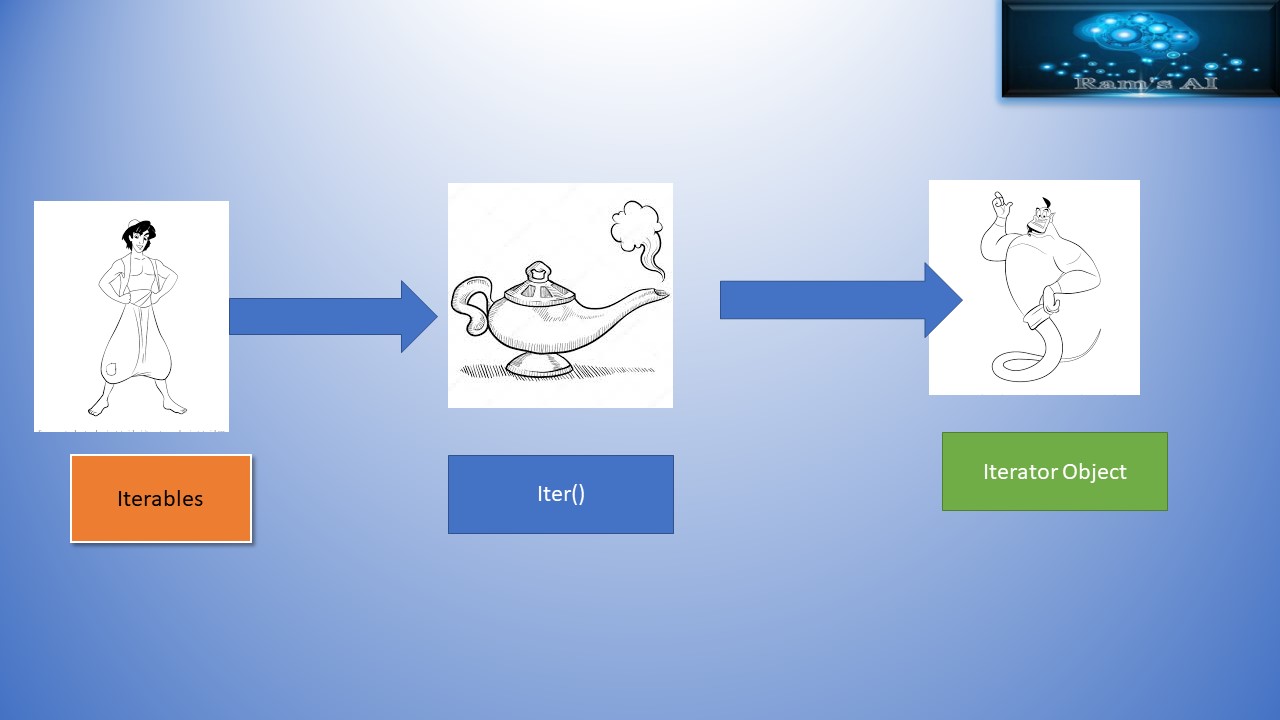
Aladdin → Iterable
Magic Lamp → Iter()
Genie → Iterator

In the above example the list is the iterable and it uses the iter(list) function to create an iterator for list. Now we can use the Next(iterator) to extract individual element of the iterable.
Let's meet again for another post on Generators.
Tuesday, April 28, 2020
Apache Spark Architecture and processing in breif

As
we know, Spark runs on Master-Slave Architecture.
Let’s
see the step by step process
1.First
step the moment we submit a Spark JOB
via the Cluster Mode, Spark-Submit utility will interact with
the Resource Manager to Start the Application Master.
2.
Then there is a Spark Driver Programme which runs on the Application Master
container and it has no dependency with
the client Machine, even if we turn-off the client machine, Spark Job will be up
and running.
3.Spark
Driver Programme further interacts with the Resource Manger to start the
containers to process the data.
4.
The Resource Manager will then allocate containers and Spark Driver Programme
would start executors on all the allocated containers and assigns tasks to run.
5.
Executors will interact directly with the Spark Driver Programme and once the
tasks are finished on each of the executors, containers along with the tasks
will be released and the output will be collected by the Spark Driver Programme.
6.Here the
container where the Application Master runs acts as Master node and the
containers where all the executor process runs the tasks are called Slave Node.
Monday, April 20, 2020
Training steps of Artificial Neural Network along with visualization
The Training Steps for the Artificial Neural Network:

The Flowchart( Visualization) of Training steps :

Friday, April 17, 2020
Chi-Square test for Dependency between categorical variables( Independent and target variable)
A most common problem we come across Machine learning is determining whether input features are relevant to the outcome to be predicted. This is the problem of feature selection.
In the case of classification problems where input variables
are also categorical, we can use statistical tests to determine whether the
output variable is dependent or independent of the input variables.
“ Categorical variable is a variable that can take on one of a limited, and usually fixed, number of
possible values.”
Pearson’s chi-squared statistical hypothesis is an example
of a test for independence between categorical variables.
We take
an example : Is gender independent of education level? A random sample
of 395 people were surveyed and each person was asked to report the highest
education level they obtained. The data that resulted from the survey is
summarized in the following table:
|
|
High School
|
Bachelors
|
Masters
|
Ph.d.
|
Total
|
|
Female
|
60
|
54
|
46
|
41
|
201
|
|
Male
|
40
|
44
|
53
|
57
|
194
|
|
Total
|
100
|
98
|
99
|
98
|
395
|
This table is called
a contingency tableby Karl Pearson, because the intent is to help
determine whether one variable is contingent upon or depends upon the other
variable
The Chi-Squared test is a statistical
hypothesis test that assumes (the null hypothesis) that the observed
frequenciesfor a categorical variable match the expected frequenciesfor
the categorical variable. The Chi-Squared test does this for a contingency
table, first calculating the expected frequencies for the groups, then
determining whether the division of the groups, called the observed
frequencies, matches the expected frequencies.
The resultof the test is a test statisticthat
has a chi-squared distribution and can be interpreted to reject or fail to
reject the assumption or null hypothesis that the observed and expected
frequencies are the same.
When observed frequency is far from the expected frequency,
the corresponding term in the sum is large; when the two are close, this term
is small. Large values of Chi-squareindicate that observed and expected
frequencies are far apart. Small values of **Chi-square** mean the
opposite: observed are close to expected.
“ The variables
are considered independent if the observed and expected frequencies are
similar, that the levels of the variables do not interact, are not dependent.
we can interpret
the dependency of the variables in two
ways
1.
Using test statistic
2.
Using P-value
1.Using Test-statistic
We can
interpret the test statistic in the context of the chi-squared distribution
with the requisite number of degress of freedom as follows: **
- If Statistic >= Critical
Valuesignificant
result, reject null hypothesis (H0), dependent.
- If Statistic < Critical
Valuenot
significant result, fail to reject null hypothesis (H0), independent.
The
degrees of freedom for the chi-squared distribution is calculated based on the
size of the contingency table as:
degrees of freedom: (rows - 1) * (cols - 1)
2.Using
P-value
In terms
of a p-value and a chosen significance level (alpha), the test can be
interpreted as follows:
- If p-value <= alphasignificant result, reject
null hypothesis (H0), dependent.
- If p-value > alphanot significant result, fail
to reject null hypothesis (H0), independent.
For the
test to be effective, at least five observations are required in each cell of
the contingency table.
Monday, March 16, 2020
TF-IDF algorithm ( Natural Language Processing)
TF-IDF:
TF-IDF stands for Term frequency and inverse document frequency and is one of the most popular and effective Natural Language Processing techniques. This technique allows you to estimate the importance of the term for the term (words) relative to all other terms in a text.
CORE IDEA: If a term appears in some text frequently, and rarely in any other text – this term has more importance for this text.


TF-IDF stands for Term frequency and inverse document frequency and is one of the most popular and effective Natural Language Processing techniques. This technique allows you to estimate the importance of the term for the term (words) relative to all other terms in a text.
CORE IDEA: If a term appears in some text frequently, and rarely in any other text – this term has more importance for this text.
This technique uses TF(Term frequency) and IDF(Inverse document frequency) algorithms:
- TF – shows the frequency of the term in the text, as compared with the total number of the words in the text.
- IDF – is the inverse frequency of terms in the text. It simply displays the importance of each term. It is calculated as a logarithm of the number of texts divided by the number of texts containing this term.
TF-IDF algorithm:
- Evaluate the TF-values for each term (word).
- Extract the IDF-values for these terms.
- Get TF-IDF values for each term: by multiplying TF by IDF.
- We get a dictionary with calculated TF-IDF for each term.
The algorithm for TF-IDF calculation for one word is shown on the diagram.

The results of the same algorithm for three simple sentences with the TF-IDF technique are shown below.

The advantages of this vectorization technique:
- Unimportant terms will receive low TF-IDF weight (because they are frequently found in all texts) and important – high.
- It is simple to evaluate important terms and stop-words in text.
Subscribe to:
Comments (Atom)
-
 As we know, Spark runs on Master-Slave Architecture. Let’s see the step by step process 1.First step the moment we submit a Spa...
As we know, Spark runs on Master-Slave Architecture. Let’s see the step by step process 1.First step the moment we submit a Spa... -
 TF-IDF: TF-IDF stands for Term frequency and inverse document frequency and is one of the most popular and effective Natural Language ...
TF-IDF: TF-IDF stands for Term frequency and inverse document frequency and is one of the most popular and effective Natural Language ...
